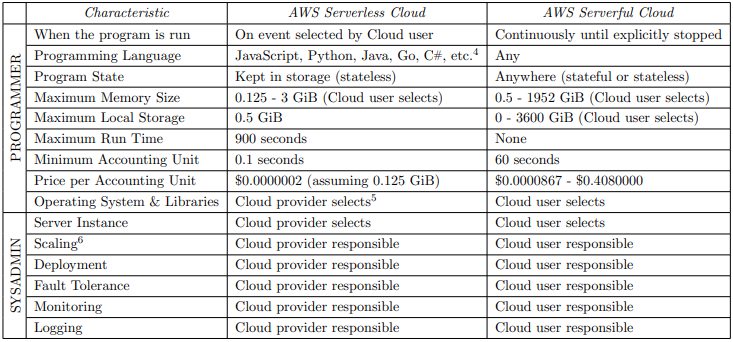
Cloud Programming Simplified
The University of California, Berkeley has published a Paper on Serverless Computing:
https://www2.eecs.berkeley.edu/Pubs/TechRpts/2019/EECS-2019-3.pdf
It gives a bit of a history and decribes how system administration operations are now handled by the cloud provider. It predicts that serverless computing will grow to dominate cloud computing.
Introduction
In 2009 there were two competing approaches to virtualization in the cloud:
Amazon EC2: Looking like a physical machine. The user can control the entire stack from the kernel upwards.
Google App Engine: application domain-specific platform with a clean separation between a stateless computation tier and a stateful storage tier.
The market embraced Amazon’s Low-Level approach. Probably because in the early days this made it easier to migrate existing workloads to the cloud.
But over time the demand was growing to have backend services without having to deal with low-level system administration.
This need was addressed by FaaS (Function as a Service) like Amazon Lambda and BaaS (Backend as a Service) Like Firebase Or Dynamo DB.
Serverless = FaaS + BaaS (including automatic scaling and billing by usage)
Emergence of serverless computing
In the cloud context, serverful computing is like programming low-Level assembly language, whereas serverless computing is Like programming in a high level language like python including automatic memory management. Container orchestration platforms Like a managed Kubernetes can be seen as an intermediate step like programming in C.
Contextualizing Server Less Computing
An innovation is the auto scaling, that is managed by the cloud provider and which works much better than serverful auto scaling that is managed by the user.
Key Projects used by the cloud providers are Firecracker by Amazon and gVisor by Google.
Edge computing offers to execute serverless functions at facilities close to the user.
Limitations
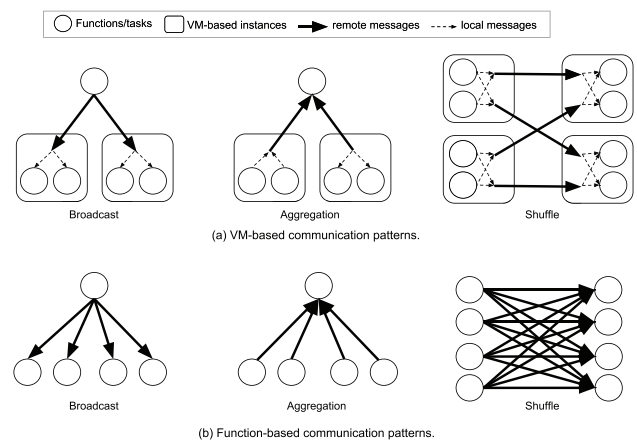
Broadcast, aggregation and shuffle are common communication primitives in distributed systems. In VM-based computing, these cause less remote messages than in serverless computing.
Typical use cases for these are machine Learning and big data analytics.
Predictions
-
We expect serverless computing to become simpler to program securely than serverful computing, benefiting from the high level of programming abstraction and the fine-grained isolation of cloud functions.
-
We see no fundamental reason why the cost of serverless computing should be higher than that of serverful computing
-
Serverful computing will be used by cloud providers to implement BaaS for applications that prove to be difficult to write on top of serverless computing, such as OLTP databases or communication primitives such as queues.
-
Serverless computing will become the default computing paradigm of the Cloud Era, largely replacing serverful computing and thereby bringing closure to the Client-Server Era.